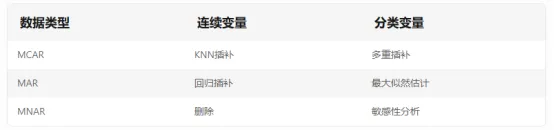
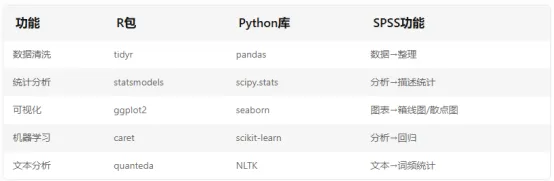
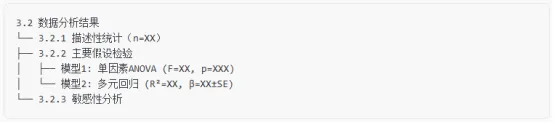
确保实验设计符合随机对照原则(RCT)或分层抽样,避免选择性偏倚使用标准化量表(如WHOQOL-BREF)并记录测量工具的信效度(Cronbach's α>0.7)保留原始数据存储凭证(如实验室日志、设备校准记录)lIQR法(全距法):Q1-1.5IQR ≤ X ≤ Q3+1.5IQRl单因素研究:ANOVA + 事后检验(Tukey HSD)l多因素研究:SEM结构方程模型 / MLM混合效应模型l纵向数据:GEE广义估计方程 / REML随机截距模型lOmega-squared(Ω²)替代p值作为效应量指标l使用Plotly/Power BI创建参数可调的可视化仪表盘l使用Cohen's forest plot展示多组比较l统计显著性:报告精确p值(如p=0.0032而非p<0.05)l临床意义:计算效应量的实际影响(如风险比HR=0.65对应15%绝对风险降低)l使用Jupyter Notebook创建数据分析流水线l注册预注册报告(如Open Science Framework)l检查样本量是否足够(使用G*Power计算功效)l采用Benjamini-Hochberg法控制FDRl预先登记分析计划(注册号:XXXX-XXXXX)通过以上系统性攻略,不仅能提升数据分析的科学严谨性,更能构建起完整的证据链体系。记住:统计显著性只是起点,真正的说服力来自效应量的临床价值、机制解释的合理性以及研究设计的严谨性。建议在论文初稿完成后,采用"盲审模拟"方式请同行评议,针对反馈意见迭代优化分析方案。-- --
--(咨询请长按扫码)
声明:信息来源网络整合及AI.本微信公众号刊载此文,是出于传递更多学习信息之目的,内容仅供参考交流之用,不代表赞同其全部观点。